3DSSD: Point-based 3D Single Stage Object Detector
arXiv link github #todo
# Main Ideas:
- Introduced Feature-Farthest Point Sampling (F-FPS)
- Introduced new sampling method called Fusion Sampling in Set Abstraction Layer
# Feature-Farthest Point Sampling (F-FPS)
- Objective when downsample:
- Remove negative points (background points)
- Preserve only positive points (foreground points, i.e: points within any instance := ground truth box)
- Therefore leverage semantic features of points as well when applying FPS
- Given two points $A$ and $B$, the criterion used to compare them in FPS is:$$C(A,B)=\lambda L_d(A,B)+L_f(A,B)$$ where - $L_d(A,B)$ is $L^2$ euclidean distance (xyz) - $L_f(A,B)$ is $L^2$ feature distance (distance between the two feature vectors) - $\lambda$ is chosen parameter, paper seems to choose $\lambda=1$ - reminder: $L^2(A,B)= \sqrt{(B_1-A_1)^2+(B_1-A_1)^2+\cdots+(B_n-A_n)^2}$ if $A$ and $B$ are $n$ dimensional vectors
- Result should be a subset of points that are less redundant and more diverse, as points are not only physically distant when sampling, but also in feature space.
# Fusion Sampling
- Downsampling to $N_m$ points with F-FPS results in: - lots of positive points -> good for regression - few negative points (due to limiting ) -> bad for classification - Why? Negative points don’t have enough neighbours #expand
- Input: $N_i\times C_i :=$ $N$ points each with feature vector of length $C$
- want to output $N_{i+1}$ points, where $N_{i+1}$ points are subset of the $N_i$ points
- F-FPS$: N_i \to \frac{N_{i+1}}{2}$ #Q
- D-FPS:$N_i \to \frac{N_{i+1}}{2}$ #Q
- grouping operation
- MLP
- MaxPool
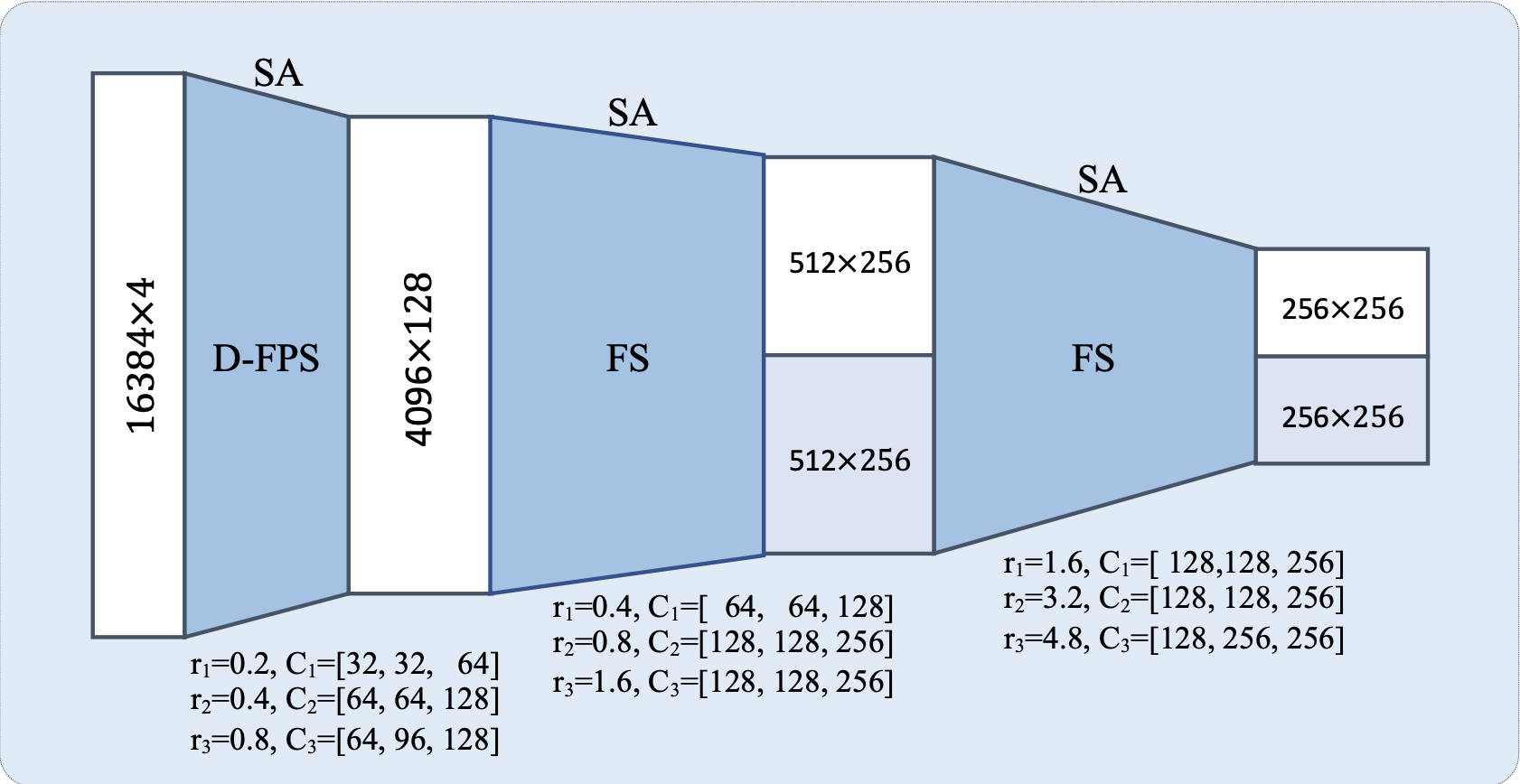
# Network walkthrough
using the following network config: 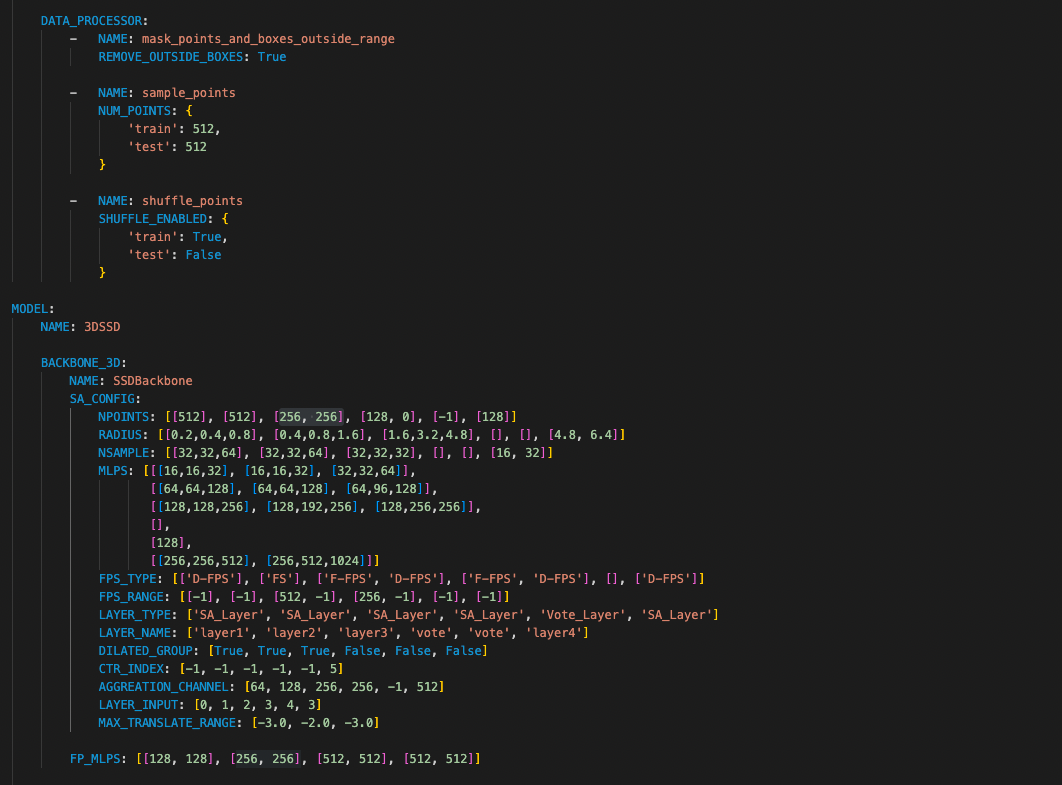
# Network Input:
- Radar pts of dim 4: $[x,y,z,RCS]$
- input size is determined by
sample_pointsinDATA_PROCESSOR: e.g.: 512 - then the feature dimension is 1 (RCS)
# Assumptions
- For each layer, the points remaining $>$
npoints. If not, there’ll be some padding/repeated points during downsampling.
# syntax
$B$: is batch size
# 3DSSD Backbone
# SA_Layer 1 (D-FPS)
Input:
- xyz: (B,512,3) <-
npoints=512 - feature: (B,1,512) <- 1 feature for 512 pts
Operations
D-FPS to sample 512 points
Grouping: create
new_feature_listball query with r=0.2, nsample=32, MLP=[16,16,32]
- new_feauture: (B,32,512,32)
Maxpool and squeeze last channel
[-1]- new_feature: (B,32,512), append to
new_feature_list
- new_feature: (B,32,512), append to
ball query with r=0.4, nsample=32, MLP=[16,16,32]
- new_feauture: (B,32,512,32)
Maxpool and squeeze last channel
[-1]- new_feature: (B,32,512) , append to
new_feature_list
- new_feature: (B,32,512) , append to
ball query with r=0.8, nsample=64, MLP=[16,16,32]
- new_feauture: (B,32,512,64)
Maxpool and squeeze last channel
[-1]- new_feature: (B,32,512) , append to
new_feature_list
- new_feature: (B,32,512) , append to
Aggregation Channel:
torch.catall features alongdim=1- new_feature: (B,32+32+64,512)
- Conv1d with
in_channel=128,out_channel=64,kernel_size = 1, batchnorm1d and ReLU- new_feature: (B,64,512)
Output:
- new_xyz: (B,512,3)
- new_feature: (B,64,512) <- 64 features for 512 pts, etc…
# SA_Layer 2 (FS)
Input
- xyz: (B,512,3) <-
npoint=512 - feature: (B,64,512) <- 64 features from layer 1
Operations
Sample 512 points via D-FPS and F-FPS, then concat them together (total pts=1024)
- Note: unlike sampling via [F-FPS,D-FPS] (see next layer), it seems like FS may select the same point more than once.
Grouping
ball query with r=0.4, nsample=32, then MLP=[64,64,128]
- new_feauture: (B,1281024,32) <- the +3 here is xyz of each sampled point
Maxpool and squeeze last channel
[-1]- new_feature: (B,128,1024), append to
new_feature_list
- new_feature: (B,128,1024), append to
ball query with r=0.8, nsample=32, then MLP=[64,64,128]
- new_feauture: (B,128,1024,32) <- the +3 here is xyz of each sampled point
Maxpool and squeeze last channel
[-1]- new_feature: (B,128,1024), append to
new_feature_list
- new_feature: (B,128,1024), append to
ball query with r=1.6, nsample=64, then MLP=[64,96,128]
- new_feauture: (B,128,1024,64) <- the +3 here is xyz of each sampled point
Maxpool and squeeze last channel
[-1]- new_feature: (B,128,1024), append to
new_feature_list
- new_feature: (B,128,1024), append to
Aggregation Channel:
torch.catall features alongdim=1- new_feature: (B,128+128+128,1024)
- Conv1d with
in_channel=384,out_channel=128,kernel_size = 1, batchnorm1d and ReLU- new_feature: (B,128,1024)
Output
- new_xyz: (B,1024,3)
- new_feature: (B,128,1024)
# SA_Layer 3 (F-FPS, D-FPS)
- Not sure why we use F-FPS and D-FPS instead of just FS, I think this is to make sure the set of points sampled $F\text{-}FPS \cap D\text{-}FPS =\emptyset$
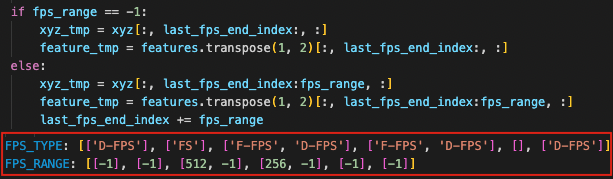
- so in this layer, F-FPS samples
[0:512]pts, then D-FPS samples from[512:1024] - but then wouldn’t this cause some sampling bias? if there are good foreground pts in
[512:1024]then F-FPS cant sample them
- so in this layer, F-FPS samples
Input
- xyz: (B,1024,3)
- feature: (B,128,1024)
Operations
Sample 256 points via D-FPS and F-FPS, then concat them together (total pts=512)
Grouping
ball query with r=1.6, nsample=32, then MLP=[128,128,256]
- new_feauture: (B,256,512,32) <- the +3 here is xyz of each sampled point
Maxpool and squeeze last channel
[-1]- new_feature: (B,256,512), append to
new_feature_list
- new_feature: (B,256,512), append to
ball query with r=3.2, nsample=32, then MLP=[128,196,256]
- new_feauture: (B,256,512,32) <- the +3 here is xyz of each sampled point
Maxpool and squeeze last channel
[-1]- new_feature: (B,256,512), append to
new_feature_list
- new_feature: (B,256,512), append to
ball query with r=4.8, nsample=32, then MLP=[128,256,256]
- new_feauture: (B,256,512,32) <- the +3 here is xyz of each sampled point
Maxpool and squeeze last channel
[-1]- new_feature: (B,256,512), append to
new_feature_list
- new_feature: (B,256,512), append to
Aggregation Channel:
torch.catall features alongdim=1- new_feature: (B,256+256+256,512)
- Conv1d with
in_channel=768,out_channel=256,kernel_size = 1, batchnorm1d and ReLU- new_feature: (B,256,512)
Output
- new_xyz: (B,512,3)
- new_feature: (B,256,512)
# SA_Layer 4 (F-FPS, D-FPS)
THIS IS THE FIRST PART OF CANDIDATE GENERATION Input
- xyz: (B,512,3)
- feature: (B,256,512)
Operations
Output:
- new_xyz: (B,128,3)
- new_feature: (B,256,128)
# Vote_Layer (n/a)
THIS IS THE SECOND PART OF CANDIDATE GENERATION
Input:
- xyz: (B,128,3)
- feature: (B,256,128)
Output:
- new_xyz: (B,128,3)
- new_feature: (B,128,128)
- ctr_offset: (B,128,3)
# SA_Layer5 (D-FPS)
Input
- xyz: (B,512,3) <- output of SA_Layer 3
- feature: (B,256,512) <- output of SA_Layer 3
- ctr_xyz: (B,127.3) <- output from vote layer
Operationa
Sample 128 points via D-FPS (total pts=128)
Grouping
- ball query with r=4.8, nsample=16, then MLP=[256,256,512]
- new_feauture: (B,512,128,16) <- the +3 here is xyz of each sampled point
- Maxpool and squeeze last channel
[-1]- new_feature: (B,512,128), append to `new_feature_list
- ball query with r=4.8, nsample=32, then MLP=[256,512,1024]
- new_feauture: (B,1024,128,32) <- the +3 here is xyz of each sampled point
- Maxpool and squeeze last channel
[-1]- new_feature: (B,1024,128), append to `new_feature_list
- ball query with r=4.8, nsample=16, then MLP=[256,256,512]
Aggregation Channel:
torch.catall features alongdim=1- new_feature: (B,512+1024,128)
- Conv1d with
in_channel=1536,out_channel=512,kernel_size = 1, batchnorm1d and ReLU- new_feature: (B,512,128)
Output
- new_xyz: (B,128,3)
- new_feature: (1,512,128)
# Detection head
- For box prediction and classification, we take the center features from the last layer of the backbone (B,512,128) reshaped into: (B*128,512) and feed it into two MLPs.
# Box prediction
- MLP = [256,256]
- FC: in_channel=512, out_channel=256
- BN then ReLU
- FC: in_channel=256, out_channel=256
- BN then ReLU
- FC: in_channel=256, out_channel=30
Output:
- (B*128,30)
note
- the 30 is:
- (x,y,z,dx,dy,dz), + 2* (12 angle bins )
- $\times 2$ because angle bin and confidence
- (x,y,z,dx,dy,dz), + 2* (12 angle bins )
# Box classification
- MLP = [256,256]
- FC: in_channel=512, out_channel=256
- BN then ReLU
- FC: in_channel=256, out_channel=256
- BN then ReLU
- FC: in_channel=256, out_channel=3 <- number of classes
Output
- (B*128,3)
# Target assignment
- After the two sets of MLP above, we need to assign predicted boxes to gt boxes. this is done via
assign_targets(self, input_dict):
- Take GT boxes and enlarge them by
GT_EXTRA_WIDTH: [0.2, 0.2, 0.2] - call
assign_stack_targets()with params:points = centers, centers are predicted centers with shape (B*128,4)gt_boxes = gt_boxes, GT boxes with shape (B,G,8) <- G = number of boxes per scene, 8: xy,z,dx,dy,dz,angle,classextend_gt_boxes=extend_gt_boxes: enlarged GT boxes with shape (B,G,8)set_ignore_flag = True: not sure what this is used atm…use_ball_constraint = False: not sureret_part_labels = False: not sureret_box_labels = True: but not sure why
- For each scene in the batch, run
roiaware_pool3d_utils.points_in_boxes_gpu()to find the predicted centroids that lie inside a gt box.- return shape is (128): values are either idx of the gt box it lies in, or -1 if its background
- create flag:
box_fg_flag = (box_idxs_of_pts >= 0)
- if
set_ignore_flag = True, then do the same for the extended gt boxes.- `fg_flag = box_fg_flag
ignore_flag = fg_flag ^ (extend_box_idxs_of_pts >= 0)- note that
^is xor gate in other flag, we only want to ignore flag points that are ONLY in the extended gt box, or ONLY in the gt box
- note that
- then
point_cls_labels_single[ignore_flag] = -1, gt_box_of_fg_points = gt_boxes[k][box_idxs_of_pts[fg_flag]]box_idxs_of_pts[fg_flag]: is a 1D tensor with indices of the gt box each pt lies in. e.g: [0,4,2,4,0,1,…]- then
gt_box_of_fg_pointsis a 2D tensor of shape (M,8) where M is the number of pts that are inside a gt box, with the associated gt box.
point_cls_labels_single[fg_flag] = 1 if self.num_class == 1 else gt_box_of_fg_points[:, -1].long()- [-1] is the class of the gt, so this gets the label and puts it into a 1D tensor.
- if
ret_box_labels and gt_box_of_fg_points.shape[0] > 0:, i.e. if there are points that lie inside gt boxes,- call
fg_point_box_labels = self.box_coder.encode_torch()with params:gt_boxes=gt_box_of_fg_points[:, :-1]: so just all boxes, with x,y,z,dx,dy,dz,anglepoints=points_single[fg_flag], all predicted centers that lie inside gt boxgt_classes=gt_box_of_fg_points[:, -1].long()class of gt boxes.- but not used if
self.use_mean = False, this is set via'use_mean_size': FalseunderBOX_CODER_CONFIG
- but not used if
- function basically assigned a label based on residuals for each pt based on the gt box it lies in.
- i.e. the label for each point is different between point (x,y,z) and box center +
- log() of dx dy dz of gt box
- bin of angle + residual
- total = length of 8
- call
point_box_labels_single[fg_flag] = fg_point_box_labels- assign the points their new labels
point_box_labels[bs_mask] = point_box_labels_single- assign it to the “outer” list (where all labels for each sample in the batch will be)
- after doing this for all samples in batch: concat all
gt_box_of_fg_pointsinto a tensorgt_boxes_of_fg_points - Return the following dict.
{kind=link}
| |